

Introduction & Welcome!
Reproducible Research Data and Project Management in R
R-RSE
https://acce-rrresearch.netlify.app/
The paper is the advertisement
“an article about computational result is advertising, not scholarship. The actual scholarship is the full software environment, code and data, that produced the result.”
John Claerbout paraphrased in Buckheit and Donoho (1995)
Lessons from the Reproducibility/Replicability crisis
Many issues statistical and a results of broken Academic incentive systems.
Much can be tackled by transparency and better computational literacy.

Reproducible Research in Computational Science
ROGER D. PENG, SCIENCE 02 DEC 2011 : 1226-1227
Reproducibility has the potential to serve as a minimum standard for judging scientific claims when full independent replication of a study is not possible.

Reinventing discovery by open sourcing science
Nielsen, Michael. Reinventing Discovery: The New Era of Networked Science. Princeton University Press, 2012. JSTOR, www.jstor.org/stable/j.ctt7s4vx.
Sharing resources
Collective intelligence
Mass collaboration

gapminder.org: today
Fighting global misconceptions with data
Research meta-responsibilities
We need better digital curation of the workhorses of modern science: code & data
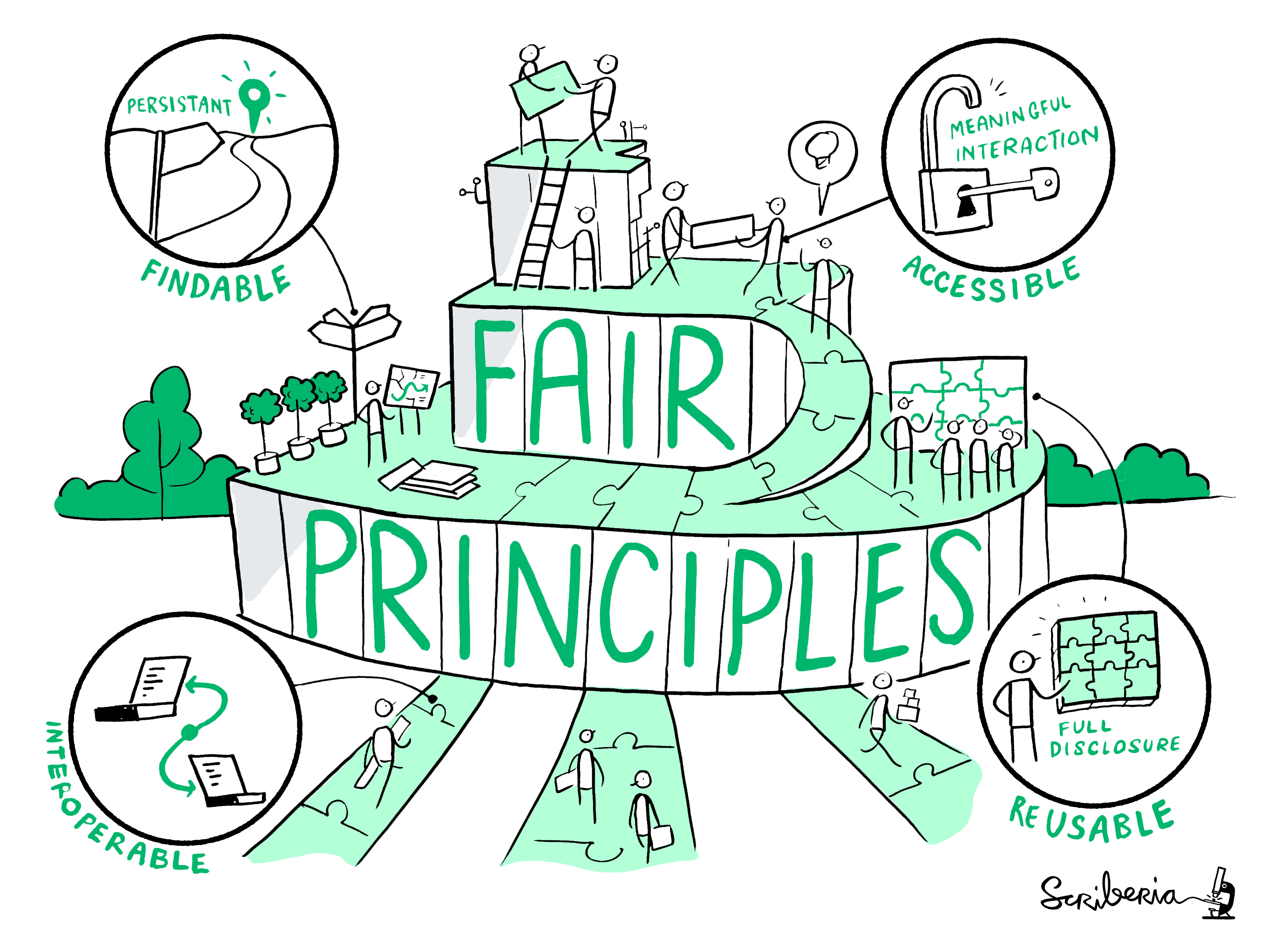
aim to create secure materials that are FAIR findable, accessible, interoperable, reusable
Research meta-responsibilities
Think about traceability and provenance.
Follow community conventions.
Prepare it to share it.
We all need to do our bit!

Yourselves!
Be your own best friend:

Ultimately it’s about getting a handle on our research materials
“Agree on a community convention…then follow it””

The concept of a Research Compendium
“ …We introduce the concept of a compendium as both a container for the different elements that make up the document and its computations (i.e. text, code, data, …), and as a means for distributing, managing and updating the collection.”

Why Research Compendia?
Kartik Ram: rstudio::conf 2019 talk
Research Compendium Principles

Kartik Ram: rstudio::conf 2019 talk
R + Rstudio
Next generation data science powerhouse
Backed by a diverse and active community of learners, users and developers
![]()
![]()
![]()

![]()
Get back
![]()